
By Adrian Cockcroft, Partner & Analyst, OrionX
![]() HPC luminary Jack Dongarra’s fascinating comments at SC22 on the low efficiency of leadership-class supercomputers highlighted by the latest High Performance Conjugate Gradients (HPCG) benchmark results will, I believe, influence the next generation of supercomputer architectures to optimize for sparse matrix computations. The upcoming technology that will help address this problem is CXL. Next generation architectures will use CXL3.0 switches to connect processing nodes, pooled memory and I/O resources into very large, coherent fabrics within a rack, and use Ethernet between racks. I call this a “Petalith” architecture (explanation below), and I think CXL will play a significant and growing role in shaping this emerging development in the high performance interconnect space.
HPC luminary Jack Dongarra’s fascinating comments at SC22 on the low efficiency of leadership-class supercomputers highlighted by the latest High Performance Conjugate Gradients (HPCG) benchmark results will, I believe, influence the next generation of supercomputer architectures to optimize for sparse matrix computations. The upcoming technology that will help address this problem is CXL. Next generation architectures will use CXL3.0 switches to connect processing nodes, pooled memory and I/O resources into very large, coherent fabrics within a rack, and use Ethernet between racks. I call this a “Petalith” architecture (explanation below), and I think CXL will play a significant and growing role in shaping this emerging development in the high performance interconnect space.
This story starts 20 years ago, when I was a Distinguished Engineer at Sun Microsystems and Shahin Khan, now a partner at the OrionX technology consultancy, asked me to be the chief architect for the High Performance Technical Computing team he was running. When I retired from my Amazon VP position earlier this year and was looking for a way to support a consulting, analyst and advisory role, I reached out to Shahin again, and joined OrionX.net.
At SC22, Shahin and I went to the Top500 Report media briefing. Dongarra reviewed the latest results and pointed out low efficiency on some important workloads. In the discussion, there was no mention of interconnect trends, so I asked whether the fix lay in new approaches to interconnect efficiency. Two slides he shared later, during the conference at his Turing Award Lecture as the event keynote and during a panel discussion on “Reinventing HPC,” touch on the interconnect issue:
The Top500 HPL (High Performance LINPACK) benchmark results are now led by the Frontier system at Oak Ridge National Laboratory, an HPE/Cray system delivering more than an exaflop for 64bit floating point dense matrix factorization.
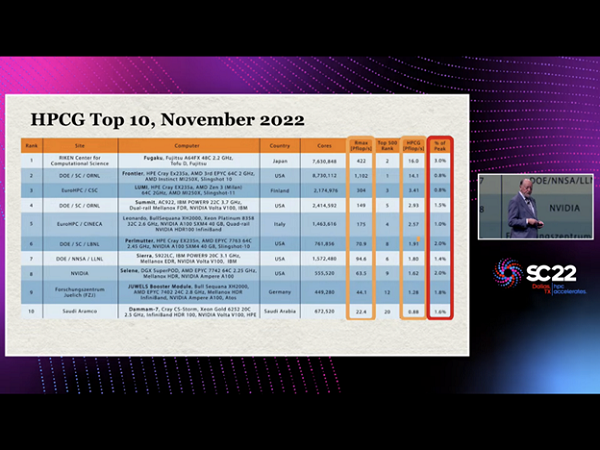
HPCG Top 10 — Jack Dongarra’s Turing Award lecture
But there are many important workloads represented by the HPCG benchmark, where Frontier only gets 14.1 petaflops, which is 0.8 percent of peak capacity. HPCG is led by Japan’s RIKEN Fugaku system at 16 petaflops, which is 3 percent of its peak capacity. This is almost four times better on a relative basis, but even so, it’s clear that most of the machine’s compute resources are idle. By contrast, the LINPACK benchmark on Frontier operates at 68 percent of peak capacity, and probably can do better with additional optimization.
Most of the top supercomputers are similar to Frontier, they use AMD or Intel CPUs with AMD, Intel and NVIDIA GPU accelerators, and Cray Slingshot or Infiniband networks in a Dragonfly+ configuration. Fugaku is very different. It uses an ARM CPU with a vector processor connected via a 6D torus interconnect. The vector processor avoids some memory bottlenecks, is more easily and automatically supported by a compiler, and the interconnect helps as well.
Over time we are seeing more applications with more complex physics and simulation characteristics, which means HPCG is becoming more relevant as a benchmark .

Over a number of briefings and conversations, we asked why other vendors weren’t copying Fugaku. We also asked about upcoming architecture improvements. Some people said that they had tried pitching an architecture like Fugaku’s but customers want Frontier-style systems. Other people saw the choice as between specialized versus more off-the-shelf technology, and that leveraging the greater investment in OTS components was the way to go in the long term.
But I think the trend is toward custom designs, with Apple, Amazon, Google and others building CPUs optimized for their own use. This week, AWS announced an HPC optimized Graviton3E CPU, which confirms this trend. If I’m right about this, Fugaku is positioned as the first of a new mainstream, rather than a special-purpose system.
I have always been particularly interested in the interconnects and protocols used to create clusters, and the latency and bandwidth of the various offerings that are available. I presented a keynote for Sun at Supercomputing 2003 in Phoenix Arizona and included the slide shown below.
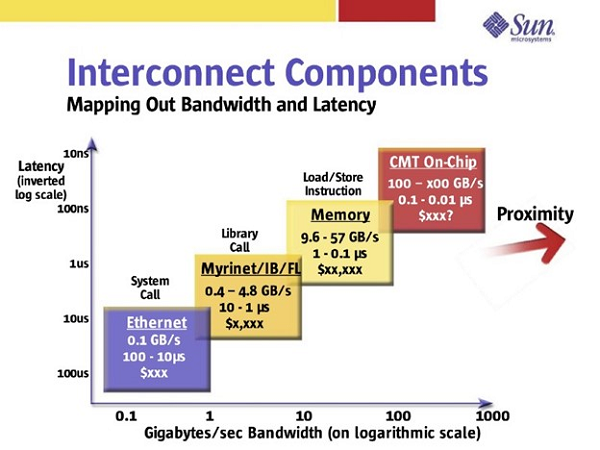
The four categories still make sense: kernel managed network sockets, user mode message passing libraries, coherent memory interfaces, and on-chip communication.
If we look at Ethernet to start with, in the last 20 years we’ve moved from the era of 1Gbit being common and 10Gbit being the best available to 100Gbit being common, with many options at 200Gbit, some at 400Gbit, 800GBit launched a year ago, and the announcement this week of 1600Gbit for a single AWS instance. The latency of Ethernet has been optimized — the HPE/Cray Slingshot used in Frontier is a heavily customized 200Gbit Ethernet based interconnect.
Twenty years ago, there was a variety of commercial interconnects like Myrinet and several Infiniband vendors and chipsets. Over the years they consolidated down to Mellanox, which is now part of NVIDIA, and OmniPath, which was sold to Cornelis by Intel. Besides being a highly mature and reliable interconnect at scale and for a variety of uses, part of the attraction of Infiniband is that it’s accessed from a user mode library like MPI, rather than a kernel call. The minimum latency hasn’t reduced much over 20 years, but Infiniband runs at 400Gbits/s nowadays.
The most interesting new development this year is that the industry has consolidated several different next generation interconnect standards around Compute Express Link — CXL, and the CXL3.0 spec was released a few months ago.
CXL3.0 doubles the speed and adds a lot of features to the existing CXL2.0 spec, which is starting to turn up as working silicon, such as the 16 port CXL2.0 switch from XConn shown in the Expo.
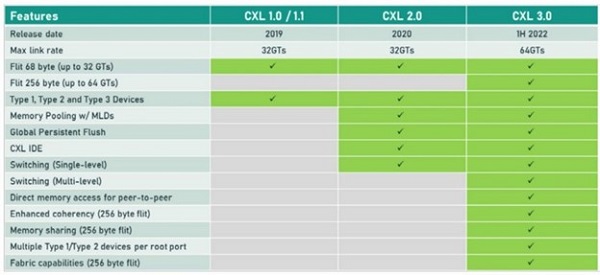
CXL is a memory protocol, as shown in the third block in my diagram from 2003, and provides cache coherent latency around 200ns, and up to 2 meters maximum distance. This is enough to cable together systems within a rack into a single CXL3.0 fabric. CXL3.0 has wide industry support: it is going to be built into future CPU designs from ARM, and earlier versions of CXL are integrated into upcoming CPUs from Intel and others. The physical layer and connector spec for CXL3.0 is the same as PCIe 6.0, and in many cases the same silicon will talk both protocols, so that the same interface can be used to connect conventional PCIe I/O devices, or can use CXL to talk to I/O devices and pooled or shared memory banks.

16-port CXL2.0 switch from XConn
The capacity of each CXL3.0 port is x16 bits wide at 64GTs which works out at 128GBytes/s in each direction, for a total of 256GBytes/s. CPUs can be expected to have two or four ports. Each transfer is a 256byte flow control unit (FLIT) that contains some error check and header information, and over 200 bytes of data.
The way CXL2.0 can be used is to have pools of shared memory and I/O devices behind a switch, then to allocate capacity as needed from the pool. With CXL3.0 the memory can also be setup as coherent shared memory and used to communicate between CPUs.
I updated my latency vs. bandwidth diagram and also included NVIDIA’s proprietary NVLINK interconnect that they use to connect GPUs together (although I couldn’t find a reference to NVLINK latency).
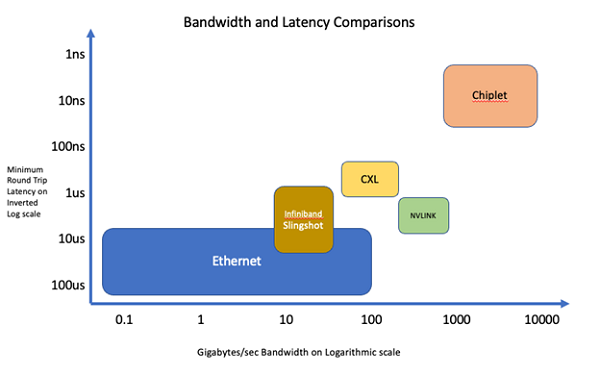 Comparing CXL3.0 to Ethernet, Slingshot and Infiniband, it offers lower latency and higher bandwidth, but has limited connections inside a rack. The way the current Slingshot networks are setup in Dragonfly+ configurations is that a group of CPU/GPU nodes in a rack are fully connected via switch groups, and there are relatively fewer connections between switch groups. A possible CXL3.0 architecture could replace the copper wired local connections, and use Ethernet for the fiber optic connections between racks. Unlike Dragonfly, where the local clusters have a fixed configuration of memory, CPU, GPU and connections, the flexibility of a CXL3.0 fabric allows the cluster to be configured with the right balance of each for a specific workload. As mentioned, I call this architecture Petalith. Each rack-scale fabric is a much larger “petal” that contains hundreds of CPUs and GPUs, tens to hundreds of terabytes of memory, and a cluster of racks would be connected by many 800Gbit Ethernet links.
Comparing CXL3.0 to Ethernet, Slingshot and Infiniband, it offers lower latency and higher bandwidth, but has limited connections inside a rack. The way the current Slingshot networks are setup in Dragonfly+ configurations is that a group of CPU/GPU nodes in a rack are fully connected via switch groups, and there are relatively fewer connections between switch groups. A possible CXL3.0 architecture could replace the copper wired local connections, and use Ethernet for the fiber optic connections between racks. Unlike Dragonfly, where the local clusters have a fixed configuration of memory, CPU, GPU and connections, the flexibility of a CXL3.0 fabric allows the cluster to be configured with the right balance of each for a specific workload. As mentioned, I call this architecture Petalith. Each rack-scale fabric is a much larger “petal” that contains hundreds of CPUs and GPUs, tens to hundreds of terabytes of memory, and a cluster of racks would be connected by many 800Gbit Ethernet links.
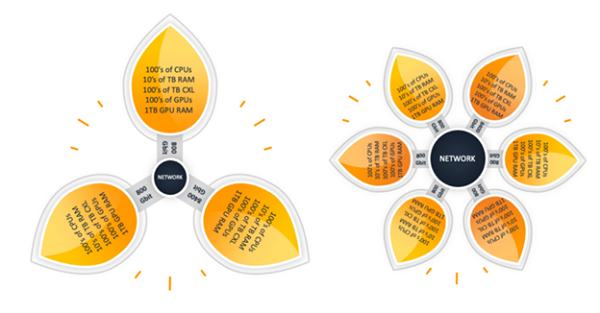
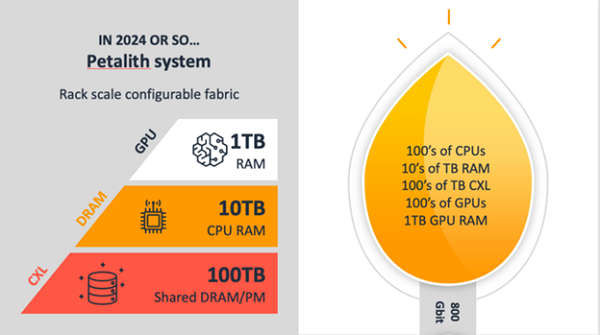 When I asked some CXL experts whether they saw CXL3.0 competing with local interconnects within a rack, they agreed that this was part of the plan . However when I asked them what the programming model would be, message passing with MPI or shared memory with OpenMP, it appeared that topic would be tackled later as the overall CXL roadmap gets defined, rationalizing the various efforts that were consolidated into CXL. There are several different programming model approaches I can think of, but I think it’s also worth looking at the Twizzler memory-oriented operating system work taking place at UC Santa Cruz. The way I think this could play out is that the rack level fabric could be reconfigured as the workload is deployed to have the optimal “petal” size for running OpenMP shared memory for that workload, with the petals connected via MPI. Sometimes it would look like a plumeria with a few large petals, and other times like a sunflower with lots of small petals.
When I asked some CXL experts whether they saw CXL3.0 competing with local interconnects within a rack, they agreed that this was part of the plan . However when I asked them what the programming model would be, message passing with MPI or shared memory with OpenMP, it appeared that topic would be tackled later as the overall CXL roadmap gets defined, rationalizing the various efforts that were consolidated into CXL. There are several different programming model approaches I can think of, but I think it’s also worth looking at the Twizzler memory-oriented operating system work taking place at UC Santa Cruz. The way I think this could play out is that the rack level fabric could be reconfigured as the workload is deployed to have the optimal “petal” size for running OpenMP shared memory for that workload, with the petals connected via MPI. Sometimes it would look like a plumeria with a few large petals, and other times like a sunflower with lots of small petals.
 This week AWS announced their first HPC optimized CPU design, and this should all play out over the next two to three years. I expect roadmap level architectural concepts along these lines at SC23, first prototypes with CXL3.0 silicon at SC24, and hopefully some interesting HPCG results at SC25. I’ll be there to see what happens, and to see if Petalith catches on.
This week AWS announced their first HPC optimized CPU design, and this should all play out over the next two to three years. I expect roadmap level architectural concepts along these lines at SC23, first prototypes with CXL3.0 silicon at SC24, and hopefully some interesting HPCG results at SC25. I’ll be there to see what happens, and to see if Petalith catches on.
Adrian Cockcroft is a Partner & Analyst the OrionX technology consulting firm.


Hi Adrian,
It is a great article! Enjoyable to read and very in-depth.
I am the VP of Product at Xconn Technologies, glad to see our switch board picture in your article. I must have missed you at SC22, did you talk to my colleague Joe who was also there?
Would like to connect with you and there are more CXL in coming years…
JP