
Python is now the most popular programming language, according to IEEE Spectrum’s fifth annual interactive ranking of programming languages, ahead of C++ and C. Recent Intel Distributions for Python show that real HPC performance can be achieved with compilers and library packages optimized for the latest Intel architectures. Moreover, the library packages targeted for big data analysis and numerical computation included in this distribution now support scaling for multi-core and many-core processors as well as distributed cluster and cloud infrastructures.
Intel Performance Libraries Accelerate Python Performance for HPC and Data Science
September 19, 2018 by
Intel MKL Speeds Up Automated Driving Workloads on the Intel Xeon Processor
March 8, 2018 by
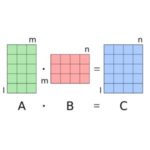
The automated driving developer community typically uses Eigen*, a C++ math library, for the matrix operations required by the Extended Kalman Filter algorithm. EKF usually involves many small matrices. However most HPC library routines for matrix operations are optimized for large matrices. “Intel MKL provides highly-tuned xGEMM function for matrix-matrix multiplication, with special paths for small matrices. Eigen can take advantage of Intel MKL through use of a compiler flag. A significant speedup results when using Eigen and Intel MKL and compiling the automated driving apps with the latest Intel C++ compiler.”
Intel MKL Compact Matrix Functions Attain Significant Speedups
February 22, 2018 by
The latest version of Intel® Math Kernel Library (MKL) offers vectorized compact functions for general and specialized matrix computations of this type. These functions rely on true SIMD (single instruction, multiple data) matrix computations, and provide significant performance benefits compared to traditional techniques that exploit multithreading but rely on standard data formats.
Intel MKL Speeds Up Small Matrix-Matrix Multiplication for Automatic Driving
January 25, 2018 by
Certain applications, such as automated driving, require low latency small matrix-matrix multiplication in real time. They use specialized libraries that can be customized for small matrix operations. Recompiling and linking those libraries with the highly optimized DGEMM routine in the Intel® Math Kernel Library 2018 can give speedups many times over native libraries.
Using the Intel C++ Compiler’s Optimization Features to Improve MySQL Performance
January 11, 2018 by

IT operations and maintenance developers have found that just by compiling the MySQL source code with the Intel C++ Compiler and turning on its Interprocedural Optimization feature, you can improve database performance from 5 to 35% compared with other compilers. “While there may be many factors affecting MySQL performance, such as hardware and software configuration, having a thoroughly optimized MySQL package is a good place to start.”
Use Intel® Inspector to Diagnose Hidden Memory and Threading Errors in Parallel Code
December 28, 2017 by
Intel Inspector is an integrated debugger that can easily diagnose latent and intermittent errors and guide users to locate the root cause. It does this by instrumenting the binaries, including dynamically generated or linked libraries, even when the source code is not available. This includes C, C++, and legacy Fortran codes.
Intel Parallel Studio 2018: Modernize Your Code
December 21, 2017 by
“Intel Parallel Studio 2018 has been designed to recognize the latest CPU architectures including the Intel Xeon Scalable processor family and the Intel Xeon Phi processors in order to get maximum performance from their differing architectures, yet remain binary compatible. With the recent introduction of the Intel AVX-512 vectorization instructions, application developers can more easily take advantage of these new instructions when developing and compiling with the Intel Parallel Studio 2018.”
Intel Advisor’s TBB Flow Graph Analyzer: Making Complex Layers of Parallelism More Manageable
December 14, 2017 by
Some deep learning applications tend to have very complex graphs with thousands of nodes and edges. To make it easier to visualize, analyze, design, and tune such complex parallel applications employing Intel TBB flow graphs, Intel provides Intel Advisor Flow Graph Analyzer (Intel FGA). It gives developers a comprehensive set of tools to examine, debug, and analyze Intel TBB flow graphs.
Intel Parallel Studio XE AVX-512: Tuning for Success with the Latest SIMD Extensions and Intel® Advanced Vector Extensions 512
December 7, 2017 by
With the introduction of Intel Parallel Studio XE, instructions for utilizing the vector extensions have been enhanced and new instructions have been added. Applications in diverse domains such as data compression and decompression, scientific simulations and cryptography can take advantage of these new and enhanced instructions. “Although microkernels can demonstrate the effectiveness of the new SIMD instructions, understanding why the new instructions benefit the code can then lead to even greater performance.”
Intel Compilers 18.0 Tune for AVX-512 ISA Extensions
October 26, 2017 by
Intel Compilers 18.0 and Intel Parallel Studio XE 2018 tuning software fully support the AVX-512 instructions. By widening and deepening the vector registers, the new instructions and added enhancements let the compiler squeeze more vector parallelism out of applications than before. Applications compiled with the –xCORE-AVX512 will generate an executable that utilizes these new high-performance instructions.

