By Rob Farber on behalf of the Exascale Computing Project
A growing number of HPC applications must deliver high performance on CPU and GPU hardware platforms. One software tool available now and showing tremendous promise for the exascale era is the open-source RAJA Portability Suite. RAJA is part of the Exascale Computing Project (ECP) NNSA software portfolio and is also supported by the ECP Programming Models and Runtimes area.
Developers of ECP and production NNSA applications acknowledge that it is straightforward to integrate RAJA into their applications to enable them to run on new hardware, be it CPU or GPU based, while maintaining high performance on existing computing platforms. [i] The RAJA Portability Suite is core to the LLNL ASC application GPU porting strategy according to the March 10, 2021 HPC Best Practices Webinar, “An Overview of the RAJA Portability Suite”, which also notes “The RAJA Portability Suite is on track to be ready for the next generation of platforms, including exascale.”
RAJA provides a kernel API that is designed to compose and transform complex parallel kernels without changing the kernel source code. Implemented using C++ templates, this API helps insulate application source code from hardware and underlying programming model details allowing Subject Matter Experts (SME) to express the parallelism inherent in their calculations while focusing on writing correct code. The expression of parallelism, as will be discussed below, requires basic knowledge of the underlying hardware platform and verification that application kernels will execute correctly in parallel.

Rich Hornung
The RAJA API enables a separation of concerns whereby developers with specialized performance analysis expertise may tune application performance for specific hardware platforms without disrupting application source code. RAJA developers also work to optimize internal software implementations allowing multiple application teams to leverage their efforts. RAJA development encompasses the expertise of over 38 contributors and 8 members of the core project team plus vendor interactions to support new hardware from IBM, NIVIDA, AMD, Intel, and Cray. Rich Hornung, RAJA project lead and a member of the High Performance Computing Group in the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory notes, “We are seeing good results of our benchmark suite on all ECP target platforms. We are also working with vendors to continue to improve performance.”
A Production Proven Performance Abstraction
Most LLNL ASC applications plus a number of ECP applications and non-ASC LLNL applications rely on the RAJA Portability Suite to run on a wide range of platforms. The LLNL institutional RADIUSS effort promotes and funds integration of the RAJA Portability Suite into non-ASC applications.
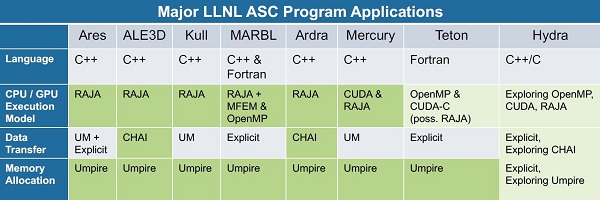
Figure 2: Major LLNL ASC application utilization. (Source: An Overview of the RAJA Portability Suite)
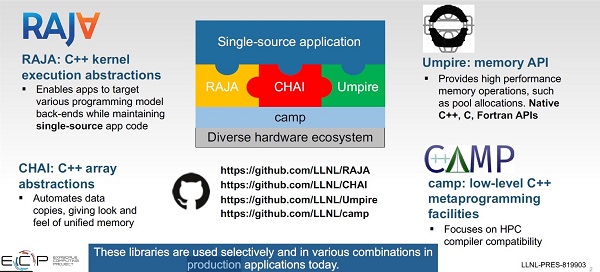
In the RAJA Portability Suite, RAJA provides the kernel execution API. Other tools in the Suite provide portable memory management capabilities. Specifically, the CHAI library implements a “managed array” abstraction to automatically transfer data, when required, to the memory space used by the device that will execute a kernel. CHAI relies on the Umpire package in the Suite, which provide a unified portable memory management API for CPUs and GPUs. An example of the interaction between these libraries when running a GPU code are illustrated in Figure 3 below.

Figure 3: An example code snippet and data flow showing the interaction of the RAJA Portability Suite components. (Source: An Overview of the RAJA Portability Suite)
The end result is an API that application programmers can use to run across a diverse hardware ecosystem. Each of RAJA, CHAI, and Umpire APIs is exposed to the application programmer as illustrated in Figure 4 (below). Figure 3 (above) provides an example set of calls. The RAJA Portability Suite also utilizes a low-level collection of macros and meta-programming facilities in the Concepts And Meta-Programming library (CAMP). A key goal of the CAMP project is to achieve wide compiler compatibility across HPC-oriented systems, thus helping to ensure portability and longevity. As shown in Figure 4, CAMP is not directly exposed to application programmers. However, they may use it in their applications if needed.

Figure 4: A Suite of libraries provide single-source portability. (Source: An Overview of the RAJA Portability Suite)
The Proof Is in the Performance
As noted at the beginning of this article, the RAJA Portability Suite is already being used in production. ECP examples illustrated in Figure 5 below show the diversity of hardware platforms and application domains that already benefit from RAJA Portability Suite.

Figure 5: The RAJA Portability Suite supports a wide diversity of applications and production hardware platforms. (Source: An Overview of the RAJA Portability Suite)
The RAJA team reports that each of these ECP applications is showing impressive performance gains on pre-exascale platforms: [ii]
- LLNL ATDM application (high-order ALE hydro simulations which uses RAJA and Umpire)
- Node-to-node speedup:
- 15x : Sierra (2 P9 + 4 V100) vs. CTS-1 Intel Cascade Lake (48 core CPUs)
- 30x : Sierra vs. Astra (Cavium ThunderX2 28 core CPUs)
- SW4 application (high-resolution earthquake simulations which uses RAJA and Umpire)
- Node-to-node speedup:
- 16x : Sierra vs. CTS-1 Intel Cascade Lake
- 32x : Sierra vs. CTS-1 Intel Broadwell
- GEOSX application (subsurface solid mechanics simulations which uses RAJA, Umpire, and CHAI)
- Node-to-node speedup
- 14x : Lassen (Sierra arch) vs. CTS-1 Intel Cascade Lake
- ExaSGD application (power grid optimization which uses RAJA and Umpire)
- Adopted RAJA and Umpire approximately 8 months ago as of March 2021
- Parts of code running on Tulip (Frontier EA system) with good performance
- Node-to-node speedup
- Node-to-node speedup:
- Node-to-node speedup:
A Useful Co-design Tool
The RAJA team reports that the RAJA Performance Suite is an essential co-design tool to work with hardware and compiler vendors to improve the performance of the RAJA Portability Suite on new architectures. The Performance Suite is a collection of diverse numerical kernels that exercise a wide range of RAJA features in ways they are used in applications. Each kernel in the Performance Suite is implemented in multiple RAJA and non-RAJA (baseline) variants for each supported programming model back-end (e.g., OpenMP, CUDA, HIP, etc.) Figure 6 (below) compares the performance of RAJA and baseline variants of various kernels in the RAJA Performance Suite for CUDA and HIP, used to run on NVIDIA and AMD GPUs, respectively.

Figure 6: Speedup of select RAJA variants of Performance Suite kernels relative to baseline variants for CUDA and HIP. Speedup of one indicates equivalent performance. Speedup values greater/less than one indicate RAJA variants are faster/slower than baseline. (Source LLNL)
The following figure shows the performance of recently added SYCL-based kernels. Along with CUDA and HIP, new RAJA SYCL support enables RAJA applications to run on GPU systems from all GPU vendors (NVIDIA, AMD, and Intel) whose hardware is deployed in production systems at US DoE laboratories.

Figure 7: Speedup of select RAJA variants of Performance Suite kernels relative to baseline for CUDA, HIP, and SYCL (Source LLNL)
Reports from application users indicate that the RAJA Portability Suite is:
- Easy to leverage features and/or optimizations developed for other applications
- Easy to grasp for all application developers
- Easy to integrate with existing applications
- Easy to adopt incrementally
More Information
Look to the following sources for more information about the RAJA Portability Suite:
- RAJA: main RAJA project site, which includes links to user guides, team communication, and associated software projects.
- RAJA Performance Suite: collection of kernels to assess compilers and RAJA performance. Used by the RAJA team, vendors, for DOE platform procurements, and others.
- Umpire: main Umpire project site, which includes links to user guides and team communication.
- CHAI: main CHAI project site, which includes links to user guides and team communication.
- CAMP: main CAMP project site.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations. He can be reached at info@techenablement.com
[i] http://ideas-productivity.org/wordpress/wp-content/uploads/2021/03/webinar050-raja.pdf
[ii] Ibid

Another good article from Rob Farber on Exascale software ramping.
CHEERS!