
In this special guest feature, Gilad Shainer from Mellanox Technologies writes that the new GPCNeT benchmark is actually a measure of relative performance under load rather than a measure of absolute performance.
The new world of data opens the door for higher degrees of scientific simulations which enable solving problems we never thought we could solve before, and for developing advanced deep learning engines that can be utilized to improve our lives. The data center architecture has changed to support these activities, and new technologies have been developed to support the migration of the data center architecture from the old CPU-centric concept to the data-centric concept. An important part of this transition has involved the creation of new compute options, including smart and programmable interconnect solutions.
InfiniBand has long been the leading standards-based interconnect technology for high-performance computing and deep learning, and has become so now also for cloud platforms serving compute and data intensive applications. InfiniBand provides innovative In-Network Computing engines that reside on the network devices, which can perform arithmetic operations on network transformed data – operations such as data reductions, data matching and much more. Additionally, there are InfiniBand devices which include standard compute cores that can be easily programmed to perform other data related operations.
Obviously this In-Network Computing innovation, where the network becomes also a “co-processor” of the data in transit, is an addition to the core mission of the data center interconnect – namely, to move data effectively and efficiently, and to ensure that the rest of the compute resources receive their data without delay. Over the years, multiple technologies and capabilities have been developed in this area, such as RDMA, GPUDirect® RDMA, Quality of Service, adaptive routing, and congestion control. While none of these technologies is foreign to standard InfiniBand, the last two basic network capabilities are new to the newest variations of proprietary networks.
Let’s take network congestion as an example. Network congestion is caused by two main reasons: point-to-point communications sharing the same network path while other paths are not being used; and many-to-one communication patterns in which the single receiver is incapable of consuming all the data coming from many senders concurrently.
Adaptive routing is the mechanism to overcome network congestion caused by the imbalanced spread of point-to-point network communications. InfiniBand adaptive routing has proven to deliver 96% network utilization, as measured using the MPIGraph benchmark by Oak Ridge National Laboratory (Source: “The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems,” Sudharshan S. Vazhkudai, Arthur S. Bland, Al Geist, et al). InfiniBand allows fine-grain adaptive routing, and offers support for several adaptive routing schemes. As such, and based on the system design and usage, the most appropriate scheme can be used to achieve optimal performance.
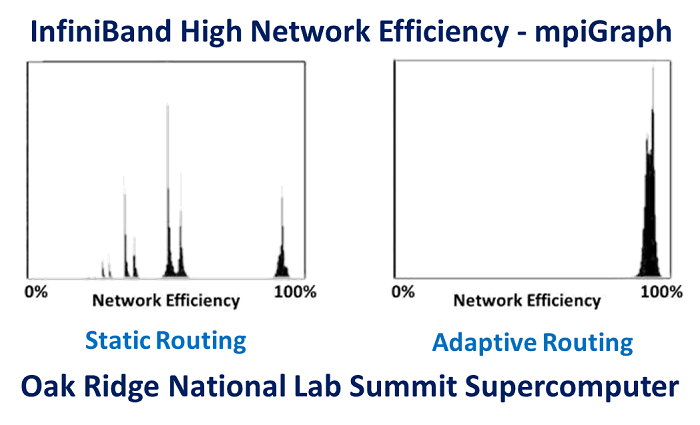
Figure 1 – mpiGraph performance results comparing static routing and adaptive routing, demonstrating the capability of InfiniBand adaptive routing to eliminate point to point congestion and to enable 96% network utilization, as measured on Summit supercomputer (from “The Design, Deployment, and Evaluation of the CORAL Pre-Exascale Systems,” Sudharshan S. Vazhkudai, Arthur S. Bland, Al Geist, et al)
The many-to-one congestion problem can be solved by congestion management or congestion control mechanisms. Key to congestion control is its reliance on the network switch to discover the many-to-one scenarios, and to trigger fast network notifications to the senders. Once a sender receives the congestion control notification, the sender reduces the amount of data it transmits to the receiver to allow for successful consumption. This way the network does not get filled with data, the switch buffers remain empty, and the many-to-one congestion scenario is avoided. Clearly, the faster the congestion notifications are issued and received, the more efficient congestion control becomes.
Back in 2010, I had the pleasure of working with the Simula laboratory team in Norway to demonstrate the InfiniBand congestion control mechanism. We built a small network with seven servers and two switches, connecting each server with a DDR 20Gb/s InfiniBand link to the switches (three servers to one switch and four servers to the second switch), and connecting the two switches with a single QDR 40Gb/s InfiniBand link. We established a case of victim flows that is caused by a many-to-one network congestion condition (victim flows are data flows that are not part of the many-to-one communication case, but suffer performance loss due to that congestion). We then demonstrated that InfiniBand congestion control both eliminates the network congestion, and prevents the development of victim flows.
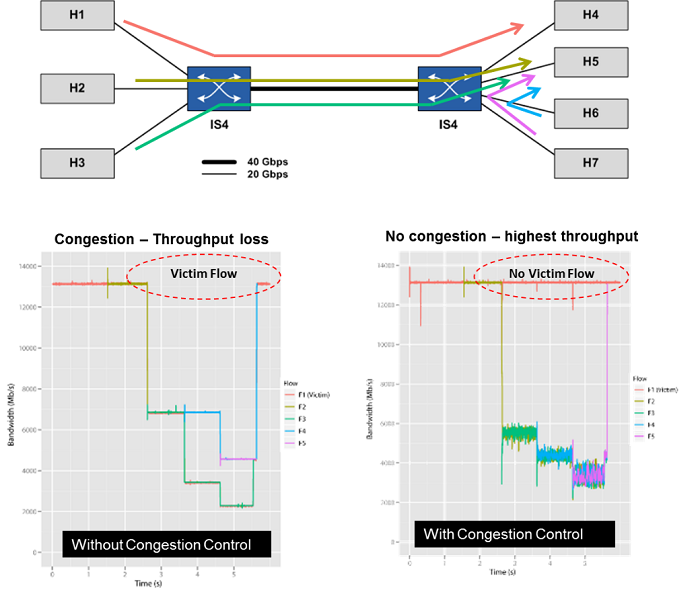
Figure 2 – Network performance with and without InfiniBand congestion control – demonstrating how InfiniBand congestion control eliminates many-to-one congestion and victim flows (from “first experiences with congestion control in InfiniBand hardware” paper, 2010)
Needless to say, the InfiniBand congestion control hardware mechanism has undergone multiple improvements and enhancements since 2010. For example, the latest HDR 200Gb/s InfiniBand switches and adapters support a fast detection and communication mechanism for effective and efficient congestion control.
We recently witnessed the introduction of a new network benchmark called Global Performance and Congestion Network Test (GPCNeT). This GPCNeT benchmark is an MPI level test designed to measure the impact of background traffic on random-ring latency and bandwidth, and on small-data MPI Allreduce operations. This raises the question of why has it suddenly become so important to create such a benchmark, and why not ten years ago? The main reason is that proprietary networks have had no support for congestion control until just now, and because congestion control has just been introduced in a new creation of a proprietary network.
At high level, the GPCNeT benchmark measures the three MPI operations, each separately in two scenarios: one, with part of the cluster nodes running one of MPI operation while the rest of the nodes are idle; and second, with part of the nodes running the same MPI operation while the rest of the nodes inject noise data into the fabric, creating many-to-one operations and network congestion. Then both results are compared per operation to yield a GPCNeT benchmark score.
The GPCNeT benchmark is actually a measure of relative performance under load rather than a measure of absolute performance. Therefore, GPCNeT cannot rank networks as being faster or slower than each other. With GPCNeT, a network that provides MPI Allreduce latency of 2 micro seconds without congestion and 3 micro seconds with congestion can be wrongly considered worse than a network that provides 100 micro seconds of latency without congestion and 110 micro seconds with congestion! (We all know that the lower the latency the better the network.) But this is the fault of the GPCNeT benchmark: it hides the real latency performance of a network.
Furthermore, the benchmark considers 8 bytes (for MPI Allreduce) to be the important data size, while congestion noise is based on large messages. Not to say that 8-byte MPI Allreduce is not relevant, but larger data size reductions and other collectives can have far larger impact on application performance – deep learning for one. Additionally, 8-byte data exchanges are indeed used, but much larger data messages (from hundreds to thousands to millions of bytes) are used much more often, and have significantly higher impact on application performance.
The above leads – and one can list many other supporting reasons – to the conclusion that GPCNeT is a very synthetic benchmark with limited benefit, and that it cannot too reliable for comparing networks in real world scenarios.
Last if we are wondering how HDR 200Gb/s InfiniBand performs under the GPCNeT benchmark, then testing results proved again HDR InfiniBand’s world-leading performance, and extremely low to no jitter. The InfiniBand congestion control mechanism was demonstrated to overcome the congestion created by the GPCNeT benchmark, and to deliver a GPCNeT congestion factor of nearly 1 – the best factor that can be achieved by this benchmark.
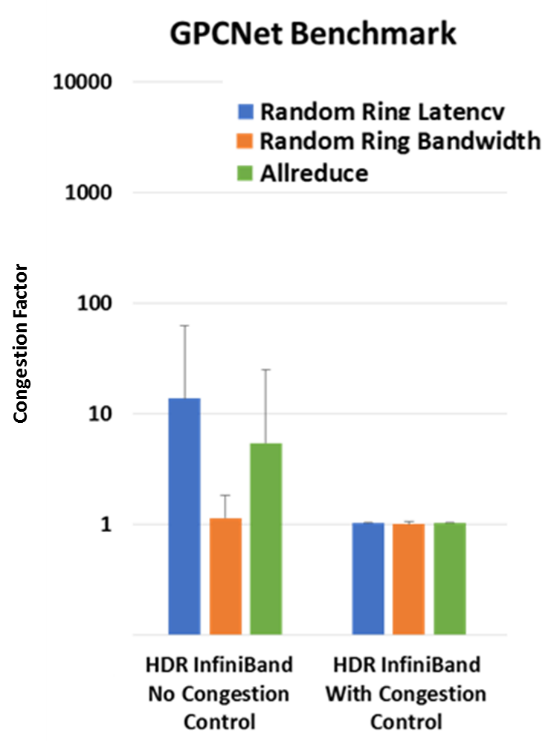
Figure 3 – GPCNeT benchmark results with HDR 200Gb/s InfiniBand, with and without congestion control. With congestion control enabled, InfiniBand has demonstrated world leading performance results.
When it comes to evaluating high-performance computing systems or interconnects, there are much better benchmarks available for use. Moreover, the ability to benchmark real workloads is obviously a better approach for determining system or interconnect performance and capabilities. The drawbacks of GPCNeT benchmarks can be much more than its benefits. GPCNoT?
About the author:

Gilad Shainer from Mellanox
Gilad Shainer has served as Mellanox’s Vice President of Marketing since March 2013. Previously, he was Mellanox’s Vice President of Marketing Development from March 2012 to March 2013. Gilad joined Mellanox in 2001 as a design engineer and later served in senior marketing management roles between July 2005 and February 2012. He holds several patents in the field of high-speed networking and contributed to the PCI-SIG PCI-X and PCIe specifications. Gilad holds a MSc degree (2001, Cum Laude) and a BSc degree (1998, Cum Laude) in Electrical Engineering from the Technion Institute of Technology in Israel.

I’m guessing these articles aren’t peer reviewed.