![]() Google today introduced the Accelerator-Optimized VM (A2) instance family on Google Compute Engine based on the NVIDIA Ampere A100 Tensor Core GPU, launched in mid-May. Available in alpha and with up to 16 GPUs, A2 VMs are the first A100-based offering in a public cloud, according to Google.
Google today introduced the Accelerator-Optimized VM (A2) instance family on Google Compute Engine based on the NVIDIA Ampere A100 Tensor Core GPU, launched in mid-May. Available in alpha and with up to 16 GPUs, A2 VMs are the first A100-based offering in a public cloud, according to Google.
At its launch, Nvidia said the A100, built on the company’s new Ampere architecture, delivers “the greatest generational leap ever,” according to Nvidia, enhancing training and inference computing performance by 20x over its predecessors.
“Google Cloud customers often look to us to provide the latest hardware and software services to help them drive innovation on AI and scientific computing workloads,” said Manish Sainani, director of Product Management at Google Cloud. “With our new A2 VM family, we are proud to be the first major cloud provider to market Nvidia A100 GPUs, just as we were with Nvidia T4 GPUs. We are excited to see what our customers will do with these new capabilities.”
 In a blog today, Goodle said the A2 VM family is intended for machine learning training and inferencing along with HPC workloads. A100 GPUs have 40 GB of HBM2 GPU memory. For multi-GPU workloads, the A2 uses Nvidia HGX A100 servers for NVLink GPU-to-GPU bandwidth of up to 600 GB/s. The VMs come with up to 96 Intel Cascade Lake vCPUs, optional Local SSD for workloads requiring faster data feeds into the GPUs and up to 100 Gbps of networking. They also provide vNUMA transparency into the architecture of underlying GPU server platforms for performance tuning.
In a blog today, Goodle said the A2 VM family is intended for machine learning training and inferencing along with HPC workloads. A100 GPUs have 40 GB of HBM2 GPU memory. For multi-GPU workloads, the A2 uses Nvidia HGX A100 servers for NVLink GPU-to-GPU bandwidth of up to 600 GB/s. The VMs come with up to 96 Intel Cascade Lake vCPUs, optional Local SSD for workloads requiring faster data feeds into the GPUs and up to 100 Gbps of networking. They also provide vNUMA transparency into the architecture of underlying GPU server platforms for performance tuning.
Google today introduced the Accelerator-Optimized VM (A2) instance family on Google Compute Engine based on the NVIDIA Ampere A100 Tensor Core GPU, launched in mid-May. Available in alpha and with up to 16 GPUs, A2 VMs are the first A100-based offering in a public cloud, according to Google. At its launch, Nvidia said the A100, built on the company’s new Ampere architecture, delivers “the greatest generational leap ever,” according to Nvidia, enhancing training and inference computing performance by 20x over its predecessors.
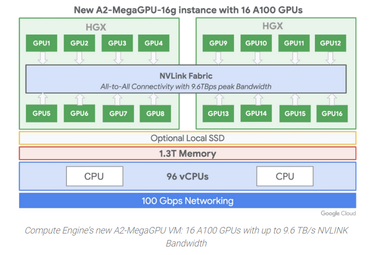
For the most demanding workloads, Google offers the a2-megagpu-16g instance with 16 A100 GPUs, offering 640 GB of GPU memory and providing an effective performance of up to 10 petaflops of FP16 or 20 petaOps of int8 when using the new sparsity feature. The instance comes with 1.3 TB of system memory and an all-to-all NVLink topology with aggregate NVLink bandwidth up to 9.6 TB/s.
The A100’s Tensor Float 32 (TF32) format provides 10x speed improvement compared to FP32 performance of Nvidia’s previous-generation Volta V100. The A100 also has 16-bit math capabilities supporting both FP16 and bfloat16 (BF16) at double the rate of TF32. INT8, INT4 and INT1 tensor operations are also supported, making A100 “an equally excellent option for inference workloads,” Google said.
 The A100’s new Sparse Tensor Core instructions allow skipping the compute on entries with zero values, resulting in a doubling of the Tensor Core compute throughput of int8, FP16, BF16 and TF32, according to Google. Also, the multi-instance group (mig) feature allows each GPU to be partitioned into up to seven GPU instances, isolated from a performance and fault isolation perspective. “Altogether, each A100 will have a lot more performance, increased memory, very flexible precision support, and increased process isolation for running multiple workloads on a single GPU,” Google said.
The A100’s new Sparse Tensor Core instructions allow skipping the compute on entries with zero values, resulting in a doubling of the Tensor Core compute throughput of int8, FP16, BF16 and TF32, according to Google. Also, the multi-instance group (mig) feature allows each GPU to be partitioned into up to seven GPU instances, isolated from a performance and fault isolation perspective. “Altogether, each A100 will have a lot more performance, increased memory, very flexible precision support, and increased process isolation for running multiple workloads on a single GPU,” Google said.
Nvidia said CUDA 11, the next version of the company’s parallel computing platform and application programming interface model, “makes accessible to developers the new capabilities of Nvidia A100 GPUs, including Tensor Cores, mixed-precision modes, multi-instance GPU, advanced memory management and standard C++/Fortran parallel language constructs.”

