
In this special guest feature from Scientific Computing World, Robert Roe talks to Antonio Peña EPEEC, project coordinator and senior researcher for the Barcelona Supercomputing Centre about progress on a European programming framework for HPC.

Antonio Peña from the Barcelona Supercomputing Centre
European researchers are working on a new programming environment for exascale computing that aims to make using these systems more efficient and programmers more productive.
The European Programming Environment for Programming Productivity of Heterogeneous Supercomputers (EPEEC) is a project that aims to combine European made tools for programming models and performance tools that could help to relieve the burden of targeting highly-heterogeneous supercomputers. It is hoped that this project will make researchers jobs easier as they can more effectively use large scale HPC systems.
As the (HPC) community works tirelessly to address the heterogeneity of upcoming exascale computers, users must be able to effectively use different architectures of processing units such as GPUs and FPGAs, heterogeneous memory systems including non-volatile and persistent memories, and networking.
The EPEEC project is aiming to overcome this challenge, having compiled five software components developed by European research institutions and companies to fine-tune and develop these tools for its programming environment. All of these tools already exist and are known to the HPC community, but, by combining these tools and integrating them and developing new features EPEEC researchers hope to develop a stable and productive platform for exascale computing.
EPEEC project coordinator and senior researcher for the Barcelona Supercomputing Center (BSC), Antonio Peña, explains that he and his colleagues saw a gap in the market for tools that could support researchers trying to make use of large HPC systems. ‘We found that in Europe there were a lot of pieces of technology that could be used together as a programming environment for exascale but, first, they needed some improvements and there needed to be some improvements to make them play better together.
Optimizing exascale
“All of the programming environment components already existed so apart from the integration we are adding features in the components themselves. For example, in OmpSs we are adding the capability to combine it with OpenACC and also with OpenMP offloading so that we get higher programming productivity when using heterogeneous systems like GPUs,” added Peña.
Directive based offloading will help domain scientists to better exploit parallelism in their code without the need for significant experience in parallel programming languages.
Offloading is needed to use devices like accelerators so you can offload to those devices, the parts of the code that are more suitable to be executed in those architectures and leave the CPU to do what it does best. This allows you to efficiently use all of the hardware resources that are available,” added Peña.
The project is integrating and improving five components used in HPC today, namely OmpSs, GASPI, Parallelware, ArgoDSM and existing performance tools from the BSC.
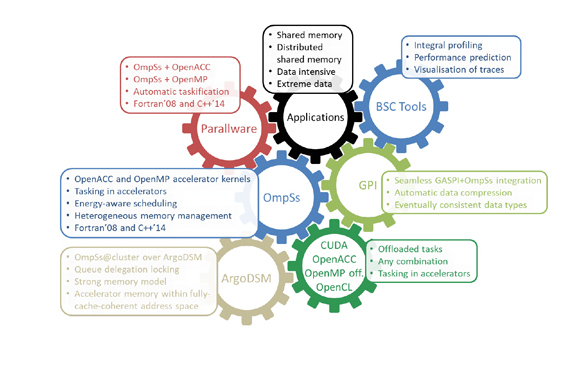
While the EPEEC project is building on these software components each has its own place in the HPC software stack. OmpSs is a shared-memory programming model based on directives and tasking, forerunner of initiatives for the OpenMP Standard. In the context of EPEEC, OmpSs is being developed to include accelerator directives and tasking within accelerators, seeking to make an impact on the OpenMP and OpenACC standardization bodies.
If successful this could lead to improved programming model composability. Additionally, the developments of a distributed-shared memory backend on top of the ArgoDSM middleware to seamlessly distribute OmpSs workloads across compute nodes will ease cluster deployments while optimizing performance with respect to state-of-the-art solutions.
GASPI is a distributed-memory programming model that is established as the European lead on one-sided internode communication. Developments in EPEEC include automatic data compression and eventually-consistent collectives, along with enhanced interoperability with runtime systems implementing intranode programming models. OmpSs+GASPI programming will offer an alternative to the ArgoDSM backend for developers seeking large-scale deployments.
Parallelware is a static analysis tool that will help users get started on porting their serial codes to parallel computing, by providing hints to directive annotation in OmpSs, OpenMP, and OpenACC.
ArgoDSM is a modern page-based distributed shared memory system first released in 2016. ArgoDSM is based on recent advances on cache coherence protocols and synchronization algorithms at Uppsala University. ArgoDSM is a page-based distributed shared virtual-memory system that operates in userspace.
The project is also looking to test this new model by running existing large scale HPC applications using the AVBP, DIOGENeS, OSIRIS, Quantum ESPRESSO, and SMURFF. Coming from different fields and covering compute-intensive, data-intensive, and extreme-data scenarios, these applications serve as co-design partners and will be used to provide pre-exascale demonstrations of the programming model in action.
“We have five big applications that we aim at running and adapting these big applications which have plenty of tradition under them. It is a challenge to run those old and complex codes in a new environment but it is also very valuable to us because they help us to better understand their needs,” notes Peña.
The main goal is to achieve something that is production-ready. We aim at this because we start from components that are themselves already production-ready. So far we are testing the new features which are pretty advanced. We are about to publicly release the midterm prototype and since we are about to release most of the features that we are developing, I am confident that in a year and a half thanks we will achieve our goal of production-ready code,” said Peña.
“In Parallelware we will have further support for tasking for OmpSs and directive-based programming with accelerators. For GASPI we will have automatic compression, and also eventually consistent data types. We are integrating the version of OmpSs@cluster on top of ARGO DSM. This will add more efficiency in quickly distributing the tasks among a cluster. This will also provide better code maintainability for us,” stated Peña.
Lowering the barrier to HPC
Peña stressed that many of the improvements developed in this project are aimed at domain scientists that do not have large amounts of experience using HPC programming frameworks. Parallelware, for example, is aimed at helping users express parallelism in their code. Allowing domain scientists to efficiently use accelerators.
We use Parallelware as a starting point for application developers to help them parallelise and use accelerators based on directives. It will help users to start annotating their code with directives both to use CPU and GPU/FPGAs. That is an optional starting point but the entire project is aimed at improving coding productivity and that is the perfect starting point for such a project,” stated Peña. “It is aimed at more towards people that do not have experience writing parallel code.”
“This project is aimed at the majority of scientists that may not have the passion or the time to understand low-level [coding] and to get their science on the systems as fast as possible. They do not care if they have lost some percentage of the machine, they want to get their code run on the system as soon as possible with more than reasonable efficiency,” stated Peña.
The integration of ArgoDSM with the EPEEC framework will work differently than some other components as it will not be directly exposed to application developers, instead the software will sit under OmpSs.
“In OmPSs we have two flavours, both of which use more or less the same interface with the user. One is like OpenMP tasking more or less but we have a version called OMPS cluster in which the different tasks the user creates are automatically distributed across the cluster nodes. That is also meant to increase productivity as those developers who do not want to mess with OpenMP or OpenMP + MPI. They can just code ‘shared memory’ and then let the runtime distribute on distributed memory,” stated Peña.
ArgoDSM system provides a virtual view shared memory view in a distributed memory system. The EPEEC researchers are developing an OmpSs@cluster version that is currently being used with MPI but eventually will be used directly with ArgoDSM.
This is a very efficient component that does smart data movement s across compute nodes and it is much more simple to code than using MPI because it exposes a shared memory system and does the distributing for us,” added Peña.
With exascale computing on the horizon, there are a number of challenges both in terms of the physical challenges of creating an exascale system – particularly within the given 20 MW power budget. However, beyond the creation of exascale supercomputers, it is clear that there is still some way to go before these systems can be used efficiently. If this project is successful it will go a long way towards increasing the productivity of HPC in Europe.
This story appears here as part of a cross-publishing agreement with Scientific Computing World.

