By Rob Farber on behalf of the Exascale Computer Project
Message Passing Interface (MPI) has been the communications backbone for distributed high-performance computing (HPC) scientific applications since its introduction in the 1990s. MPI is still essential to scientific computing because modern HPC workloads are too demanding for any single computational node to handle alone. Instead, scientific applications are distributed across many computational nodes. It is this combined distributed computational throughput – enabled by MPI – that provides the petascale and soon-to-be-exascale performance of the world’s largest supercomputers.
The MPICH library is one of the most popular implementations of MPI.[i] Primarily developed at Argonne National Laboratory (ANL) with contributions from external collaborators, MPICH has adhered to the idea of delivering a high-performance MPI library by working closely with vendors in which the MPICH software provides the link between the MPI interface used by applications programmers and vendors who provide low-level hardware acceleration for their network devices. Yanfei Guo (Figure 1), the principal investigator (PI) of the Exascale MPI project in the Exascale Computing Project (ECP) and assistant computer scientist at ANL, is following this tradition. According to Guo, “The ECP MPICH team is working closely with vendors to add general optimizations—optimizations that will work in all situations—to speed MPICH and leverage the capabilities of accelerators, such as GPUs.”
All three upcoming US exascale systems—Frontier, Aurora, and El Capitan—are GPU accelerated. They will use MPI as their primary software communications interface via the Cray and Intel MPI libraries that are based on MPICH. [ii] [iii] For performance on these systems, GPU support is a must have. In addition to GPU support, the ECP MPICH team is adding valuable extras, such as the continuous integration of the MPICH codebase, to ensure robustness across many GPU-accelerated hardware platforms and Pilgrim, a scalable and near lossless MPI tracing tool that HPC users and systems administrators can use to gain insight into the behavior of MPI-based workloads.
Guo describes the efforts of the ECP MPICH optimization team in terms of the following three buckets.
- Add general optimizations that enable low-level vendor- and hardware-specific optimizations to increase overall performance and work in all situations.
- Increase the scale and ability of MPI to support thread interoperability.
- Include low-level support for GPU accelerators.
Bucket 1: Add General Optimizations
The ECP MPICH team is developing and integrating general optimizations into MPICH that will work in all communications scenarios with a special emphasis on the forthcoming US Department of Energy (DOE) exascale hardware platforms. Guo notes that this is a challenging problem because the team must support the efforts of multiple vendors. To achieve this, the team relies on low-level libraries, such as libfabric and libucx. These libraries provide an application programming interface abstraction for platform-agnostic access to the low-level hardware operations.
Scalability and performant network capabilities are needed to achieve exascale performance. Guo notes that network hardware is becoming more capable. Send/receive message matching is known to be part of the critical performance path for HPC communications. [iv] Send/receive message matching defines the performance of the in-order message processing—particularly the communication latency—when sending and receiving messages between source and target MPI processes.[v] For performance reasons, this capability is now largely supported by hardware. Guo notes, “Working to reduce software overhead means letting the hardware do the job, or putting it very simply, have the software stay out of the way and let the hardware do the work.”
The ECP team is also working to identify and eliminate excessive memory usage. For example, this is currently an issue with the tables used by remote processes to store the information that defines how they talk to each other. Guo notes that these tables currently “get duplicated everywhere.” While addressing this issue, the team is also refactoring the code to reduce the memory footprint at a hardware-independent level by calling libraries to handle remote direct memory access (RDMA) and other hardware capabilities.
Bucket 2: Thread Interoperability to Increase Concurrency

Yanfei Guo
Thread interoperability is traditionally a very challenging problem. As noted in the introduction, the early MPI libraries were written to support applications where only a few threads were interacting. This is no longer valid as modern hardware supports fine-grained parallelism where large numbers of threads interact within the application. Guo notes that users complain when using large numbers of threads that locking causes the threads to serialize in the communication context. This causes a serious drop-off in performance.
To support large numbers of threads efficiently, the team is working to incorporate the Virtual Communications Interface (VCI) while preserving backward compatibility for legacy applications. VCI provides a modern communications interface that addresses thread efficiency in applications where the MPI ranks are heavily multi-threaded.
Guo notes that VCI leverages the extensive discussion in the MPI forum concerning endpoints, which are used to increase communications concurrency.[vi] More specifically, Guo recommends that application programmers utilize a different MPI communicator for each thread. This gives MPICH the ability via VCI to preserve concurrency by mapping of the actions of the communicator to the best hardware implementation. Flexibility in the mapping facilitates portability across hardware implementations while also simplifying work for the programmer.
The schematic diagram in Figure 2 shows how MPI can use VCI to specify many endpoints. The performance graph on the far right compares the message rate observed by the ECP MPICH team when using a few vs. many endpoints. This graph also demonstrates the performance potential that can be portably realized when running on a future machine because of the greater concurrency that can be realized by the library without intervention by the application programmer.
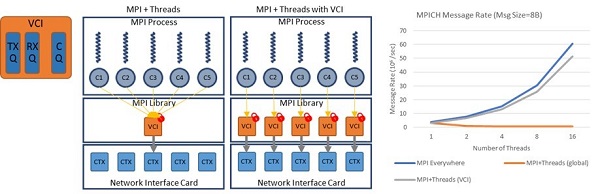
Example of how VCI enables larger number of endpoints. The graph on the far right illustrates how many endpoints can increase the MPICH message rate. (credit: Yanfei Guo)
Guo highlights the key points regarding concurrency and VCI as follows.
- VCIs are independent sets of communication resources in MPICH, and they can be mapped to different network hardware contexts.
- Having multiple VCIs allows the communication from different threads to be handled by different MPI resources, reducing contention in the MPI library
- VCIs enable multithreaded MPI applications to fully use the network hardware context without explicit programmer intervention on each hardware platform.
- The result is reduced contention and full use of network hardware, which leads to significant improvement in strong scaling performance of MPI + threads applications.
Bucket 3: Support for GPU Accelerators
To support GPU accelerators, the MPICH team divides the work into two branches: the data plane and a control plane. The data plane transfers data while the control plane allows queuing and overlapping of data transfer operations. These are discussed in detail below. Guo notes that previous MPICH work has focused on the data plane, specifically on how to move data through MPI. NVIDIA’s GPUdirect, which uses RDMA to move data to the GPU with minimal or no work by the CPU, is one example.
Data Plane
Portability is an issue when focusing solely on the data plane. Specifically, what does the software do when the native hardware capability is unavailable? Guo notes that the alternative in this case is to have the CPU directly access the network card, which incurs a hardware performance penalty in terms of CPU and Peripheral Component Interconnect Express (PCIe) bus overhead.
Similar performance and portability issues occur when the application uses a complex data type that is not supported by the hardware. In this case, the software must pack the data into a form that can be transferred efficiently by the hardware and then unpack it on the receiver side. Multilevel data structures are a good example. All these data machinations slow performance.
Control Plane
In discussing the benefits of the control plane, Guo notes that this new addition “allows the GPU to do MPI operations through what they call GPU stream-aware MPI.”
One common example is when a GPU kernel performs a computation, the result of which is required by a remote GPU kernel. Currently, the transfer of the computed result is a blocking operation because the remote kernel cannot proceed with its computation until it receives the data. Furthermore, users must manually synchronize the transfer. This creates a portability challenge and work for the programmer, as well as introduces performance issues.
The control plane concept gives the library the ability to queue data transfer operations, which opens the door to overlapping asynchronous computation and communications to increase performance and reduce or eliminate blocking operations. The concept is simple and is enabled by an extra parameter which allows queuing of the MPI operation. For portability reasons the queuing activity happens under the covers – without explicit programmer intervention – and gives the software the ability to best process the queue.
Guo refers to this change as stream-aware MPI, which allows asynchronous data transfers. He also notes that it is currently a work in progress. Stream-aware MPI enables various optimizations, such as the optimization of collective operations. Both asynchronous execution and the use of low-level machine capabilities can be exploited. Reductions, for example, are a collective operation that is heavily used in many scientific codes. They are particularly important for AI tasks such as the training artificial neural networks (ANNs) for machine learning applications. The reason is that each step in most numerical optimization algorithms require that the errors over the training data for the current set of model parameters be reduced to a single value. [vii] [viii] Most numerical algorithms take many steps in finding a good model to fit a complex training dataset.
To ensure they provide robust and performant code for supported DOE platforms, the ECP MPICH team is making heavy use of the ECP continuous integration server. Guo notes that the continuous integration effort by the ECP MPICH team is in addition to the comprehensive MPICH test suite that was created over decades of heavy MPI usage. More information can be found about the ECP continuous integration effort in the ECP technology brief “Continuous Integration: The Path to the Future for HPC.”
Pilgrim, the profiling tool developed by collaborators at the University of Illinois Urbana-Champaign, is another ECP MPICH development effort that can be used to automatically profile MPI usage of applications via the MPI profiling interface. This tool can also generate a simple test program that mimics the MPI communication pattern of the application for continuous integration and performance benchmarking.
Summary
The forthcoming generation of US exascale supercomputers requires scalability, high degrees of concurrency, and GPU support by the MPICH communications library. The ECP MPICH team’s goal is to provide this capability and advance the state of the art by developing stream-aware MPI.
The ECP MPICH effort relies on and has been performed in close collaboration with vendor partners. Resource support from the ECP includes machine time and access to the new hardware along with a continuous integration setup for real-time evaluation of ECP needs. In this way, the ECP MPICH team is working to ensure a robust, performant MPI library to support the Frontier, Aurora, and El Capitan exascale systems.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations.
[ii] https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html
[iii] https://www.olcf.ornl.gov/wp-content/uploads/2019/11/20191010_Introduction2CrayPE.pdf
[iv] https://www.osti.gov/pages/servlets/purl/1501630
[v] https://www.osti.gov/pages/servlets/purl/1501630
[vi] https://www.osti.gov/pages/servlets/purl/1140752
[vii] https://www.techenablement.com/deep-learning-teaching-code-achieves-13-pfs-on-the-ornl-titan-supercomputer/
[viii] https://www.sciencedirect.com/book/9780123884268/cuda-application-design-and-development
